학습개요
데이터 분석에서는 목적에 맞도록 데이터를 읽고 쓰는 절차가 매우 중요합니다. 분석 대상이 되는 다양한 형태의 데이터를 R에서 인식할 수 있도록 적절하게 입력하고 분석한 결과를 올바르게 저장하는 과정은 데이터 분석의 토대가 되는 매우 중요한 과정이라고 할 수 있습니다. 이 장에서는 모든 분석의 기본인 데이터의 입력과 저장을 위한 R 명령어에 대해서 학습하려고 합니다. R 콘솔(R console)에서 바로 데이터를 입력하는 방법에 대해서 살펴보고, CSV 파일을 통한 입력 및 저장에 대해서 살펴봅니다.
학습목표
1. 데이터 입력에 대해서 알아봅니다.
2. 분석한 결과를 외부 파일로 저장하는 방법을 알아봅니다.
3. 새롭게 만든 테이블을 외부 CSV 파일로 저장하는 방법에 대해 알아봅니다.
주요용어
- 데이터 입력 : R에서 각종 연산 및 명령 수행의 대상이 되는 데이터가 인식되도록 하는 과정
- 외부 파일 : R에 내장되어 있지 않고 로컬 디스크 등에 별도로 저장된 파일
- 데이터 저장 : R에서 명령을 수행한 뒤 처리된 결과를 데이터 형태로 저장하는 과정
2.1. 데이터 입력
통계분석에서 데이터의 입출력은 모든 분석의 기본 과정으로서 매우 중요하다고 할 수 있습니다. 작은 규모의 데이터는 키보드를 이용하여 바로 입력할 수 있습니다. 본 절에서는 간단한 데이터 생성방법을 알아봅니다.
2.1.1. 작업 디렉토리 설정 및 현재 디렉토리 확인
R을 활용할 때, 기본 작업경로가 길고 복잡한 경우에는 경로를 일일이 찾아 지정하는 것이 매우 번거로울 수 있습니다. 이 경우 setwd( ) 함수를 사용하여 작업 디렉토리를 변경하면 문서나 그림 파일 등에 손쉽게 접근이 가능합니다. 예를 들어, D 드라이브 하에 "datav"라는 디렉토리가 만들어져 있다고 가정한다면, 다음과 같은 명령을 통해 현 작업 디렉토리를 설정하고 모든 파일을 이 datav에 저장할 수 있으며 또한 저장된 자료를 불러오는 곳으로 활용할 수 있습니다.
> setwd('D:∖∖datav')
주의할 것은 경로의 구분은 윈도우에서 "∖∖" 또는 "/"으로 디렉토리를 구분해야 한다는 것입니다.
현재 작업 디렉토리가 적절하게 변경되었는지 확인하기 위해 작업 디렉토리 확인을 다음과 같이 수행할 수 있습니다.
> getwd()
[1] "D:/datav"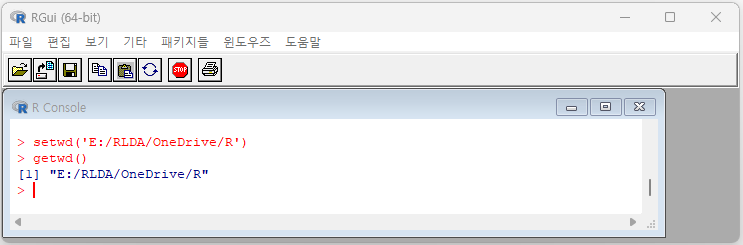
2.1.2. c( ) 함수를 이용한 입력
먼저 c( ) 함수를 이용한 가장 기본적인 데이터 입력방법을 살펴보기로 합시다. [예제 2-1]과 같이 벡터 x에 5개의 숫자를 입력합니다. 여기서 벡터란 하나 이상의 관측값을 갖는 자료구조를 의미합니다. 좌측에는 벡터 이름이 위치하며, '<-'나 "=" 연산자는 데이터가 할당됨을 의미하고, 우측에는 입력대상이 되는 데이터의 관측값이 c 함수 내에 나타나게 됩니다.
[예제 2-1] 1, 2, 3, 4, 5의 5개 관측값을 갖는 벡터 x를 생성해 봅시다.
> x <- c(1,2,3,4,5)
> x
[1] 1 2 3 4 5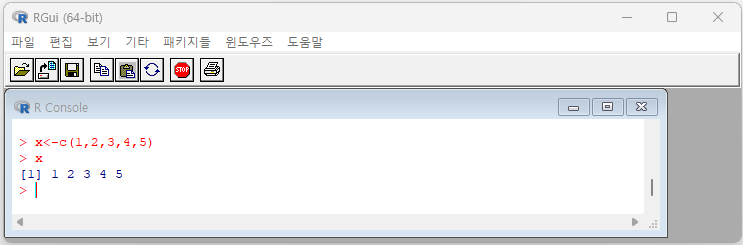
위의 예제와 유사하게 5개의 숫자로 구성된 벡터 y를 작성한다. 여기서 R 명령어 시작과 끝에 ( )를 추가하면 입력 결과를 바로 화면에 출력하게 됩니다.
[예제 2-2] 10, 20, 30, 40, 50의 5개 관측값을 갖는 벡터 y를 생성하되 입력 결과를 바로 화면에 출력해 봅시다.
> (y <- c(10,20,30,40,50))
[1] 10 20 30 40 50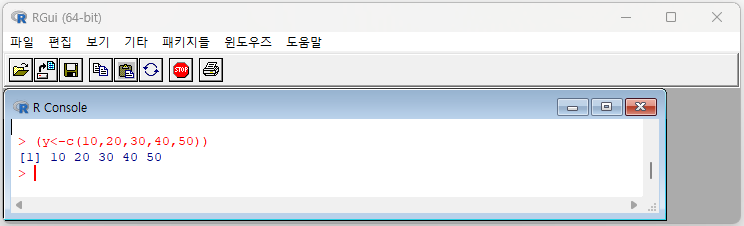
[예제 2-3] 앞의 예제에서 만든 2개의 벡터 x와 y를 결합하여 dat라는 객체(object)를 만들어 봅시다.
> dat <- cbind(x,y)
여기서 cbind는 두 벡터를 열(column) 방향으로 결합하는 함수이며 생성된 객체 dat의 형태를 다음과 같이 확인해 볼 수 있습니다.
> dat
x y
[1,] 1 10
[2,] 2 20
[3,] 3 30
[4,] 4 40
[5,] 5 50
2.1.3. scan( ) 함수를 이용한 데이터 입력
R에서는 scan( ) 함수를 활용하여 바로 데이터를 입력할 수 있습니다. 다음 함수를 실행하면 실행 프롬프트가 "1:"으로 바뀌는데 이 때 자료를 하나씩 입력하고 Enter 키를 치면 다음 값을 입력할 수 있게 됩니다. 마지막 값을 입력하고 추가로 입력 값이 없으면 그냥 Enter 키를 한 번 더 치면 입력이 종료됩니다.
[예제 2-4] scan( ) 함수를 이용하여 23, 4, 5, 6, 7의 5개 관측값을 갖는 벡터 w1을 만들어 봅시다.
> w1 <- scan()
1: 23
2: 4
3: 5
4: 6
5: 7
6:
Read 5 items
위와 같은 명령을 수행한 뒤 w1을 입력하고 Enter 키를 치면 벡터 w1에 다음과 같이 5개의 값이 입력됨을 확인할 수 있습니다.
> w1
[1] 23 4 5 6 7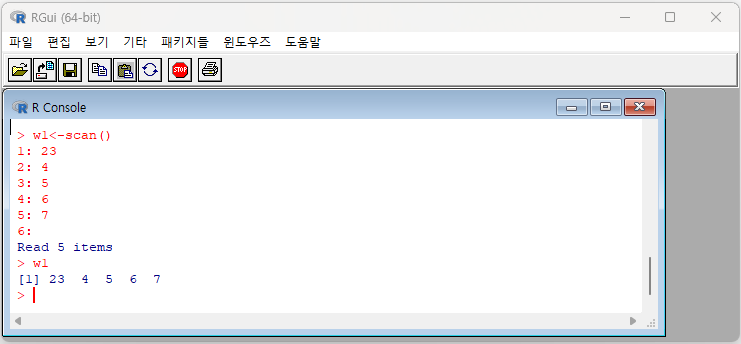
2.1.4. edit( ) 함수를 이용한 입력
다음은 데이터 탐색기 창에서 데이터를 직접 입력해 봅시다. 먼저 빈 데이터 프레임을 생성하고 데이터 편집기 창을 만들어야 합니다.
[예제 2-5] edit( ) 함수를 이용하여 데이터 프레임을 만들어 봅시다. 단, 빈 객체를 데이터 프레임으로 지정해 준 뒤 창을 열어 데이터를 입력하도록 합니다.
> dat3 <- data.frame()
> dat3=edit(dat3)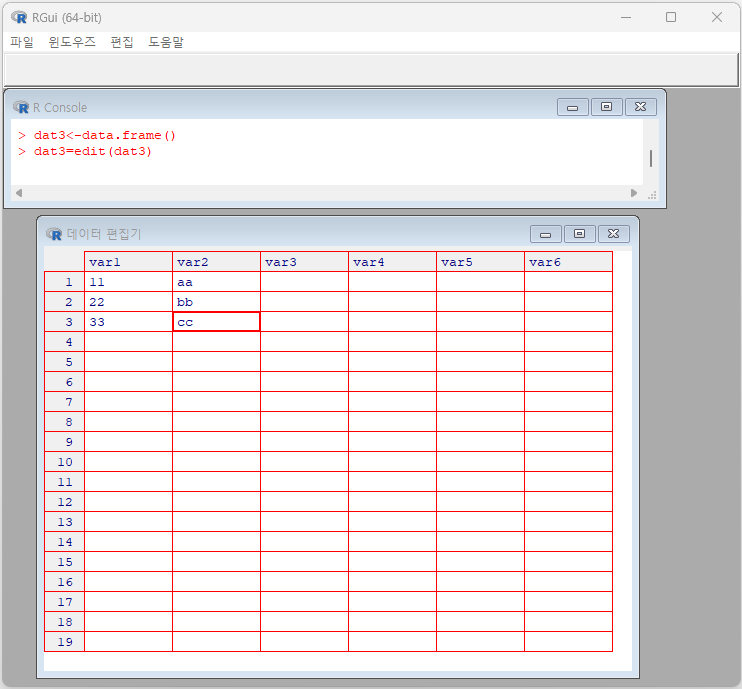
<그림 2-1>과 같이 입력 후 창닫기를 하면 입력된 자료가 dat로 저장되었음을 확인할 수 있습니다.
다음과 같이 입력하면 저장된 객체 dat3의 내용을 확인할 수 있습니다.
> dat3
var1 var2
1 11 aa
2 22 bb
3 33 cc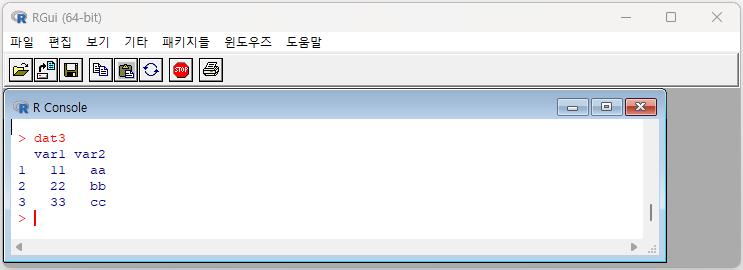
2.2. 데이터 저장
R 작업으로 생성된 데이터를 외부 파일로 저장시킬 수 있다면, 그 파일을 다른 소프트웨어에서 사용할 수 있을 것입니다. 이 절에서는 데이터를 파일로 저장하는 법에 대해서 학습해 봅시다.
2.2.1. sink( ) 함수를 활용한 출력 결과 파일 저장
함수 sink( )를 활용하여 화면에 출력된 모든 결과를 파일로 저장할 수 있는데, 시작 시 [예제 2-6]과 같이 저장할 파일명을 지정하고 원하는 함수를 실행한 후 종료 시 sink( )로 마감하면 됩니다.
[예제 2-6] R의 기본 패키지에 내장된 데이터 중에는 iris라는 데이터세트가 있습니다. sink( ) 함수를 이용하여 iris의 기술통계량을 외부 파일 printa.txt로 저장해 봅시다. 단, 기술통계량을 산출하기 위해서는 summary( ) 함수를 사용하세요.
> sink('printa.txt')
> summary(iris)
> sink()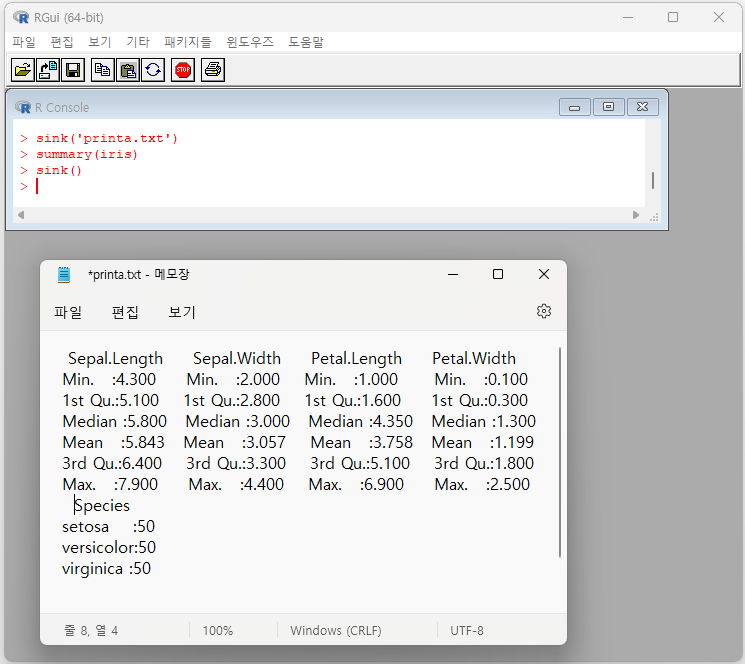
윈도우 탐색기에서 printa.txt를 메모장에서 열면 위와 같은 summary 결과가 저장되었음을 확인 할 수 있습니다.
2.2.2. write.csv( ) 함수를 이용한 데이터 저장
R에서 생성된 객체(object)는 외부 파일로 저장할 수 있는데 경로를 별도로 지정하지 않으면 이 파일은 이미 설정된 작업 디렉토리에 저장됩니다.
[예제 2-7] R의 작업경로가 "D:/datav"로 지정되어 있다고 가정합시다. [예제 2-3]에서 생성한 객체를 이 디렉토리에 "dat_exam1.csv"라는 파일로 저장해보세요. 또한 해당 경로에 csv 파일이 저장되어 있는지 확인하세요.
작업경로가 이미 "D:/datav"로 지정되었다고 가정하면 다음과 같이 write.csv( ) 함수를 통해 간단하게 파일을 저장할 수 있습니다. 함수 내에 객체명과 저장 파일 이름을 병기해 주면 됩니다.
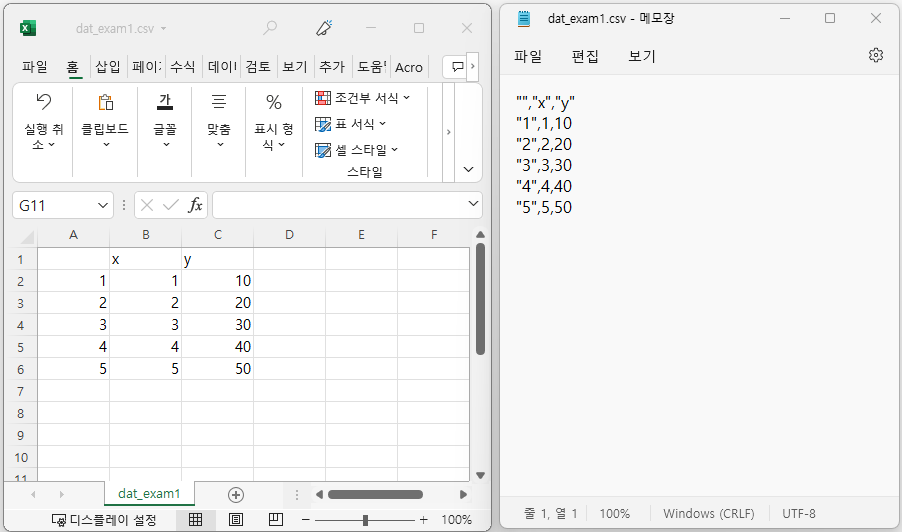
> write.csv(dat,'dat_exam1.csv')
데이터 포맷 csv(comma separated values)는 엑셀, 노트패드 등 다양한 프로그램에서 쉽게 저장 및 편집을 할 수 있는 데이터 포맷입니다. 비교적 적은 용량으로 데이터를 저장할 수 있다는 장점이 있습니다. 2개의 벡터 x, y를 저장하였지만 dat_exam1.csv 파일을 확인하면 행의 이름(번호)까지 저장되었고, 이 행에 대한 변수명은 존재하지 않는 것을 확인할 수 있습니다. 메모장을 열어 확인해 보면, 엑셀을 통해 확인한 결과와 유사하나 관측값들 사이가 콤마로 구분되어 있음을 알 수 있습니다(그림 2-2).
2.2.3. write.table( ) 함수를 이용한 데이터 저장
write.csv( )와 유사한 함수로서 write.table( ) 함수가 있습니다. 이 함수도 R의 객체를 외부로 저장한다는 점에서는 유사하지만, 기본적으로 지정되어 있는 옵션상 차이점이 있습니다. 다음 예제를 살펴봅시다.
[예제 2-8] R의 객체 dat를 다음과 같이 dat_exam2.txt라는 텍스트 파일로 저장하고 write.csv( ) 함수를 사용할 경우와 비교하여 어떠한 차이점이 발생하는지 설명해 봅시다.
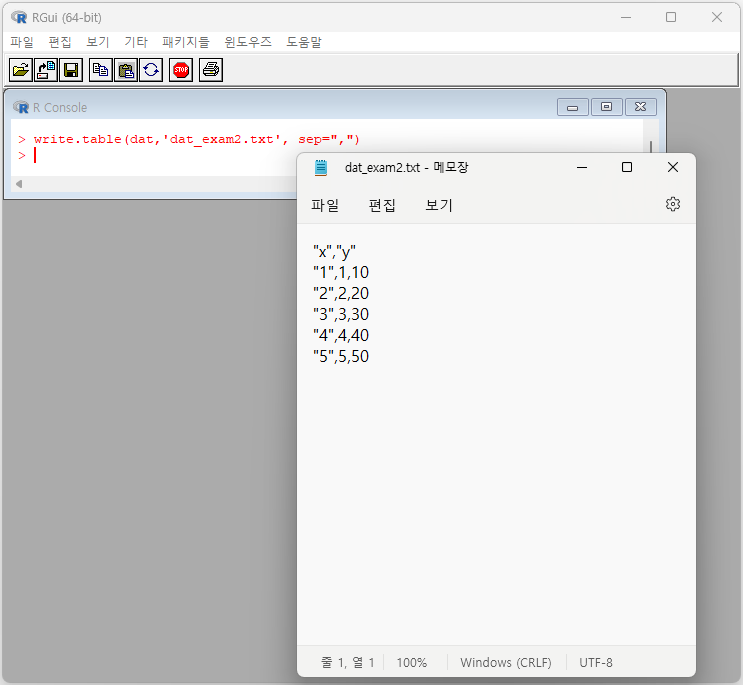
> write.table(dat,'dat_exam2.txt')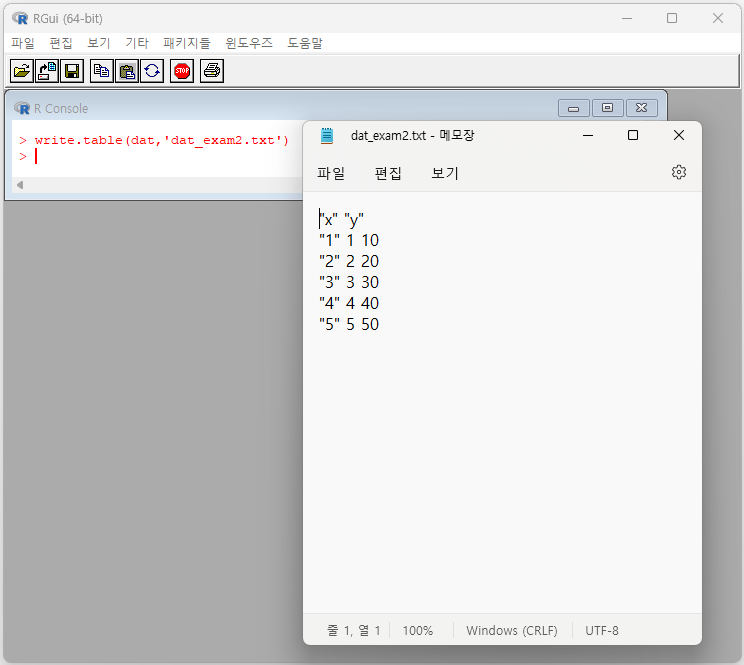
write.table( ) 함수를 이용할 경우에는 기본적으로 콤마 대신 공백(탭)을 기준으로 관측값을 구별하게 됩니다. write.table( ) 함수를 쓰면서도 콤마를 이용하여 관측값을 구별하기 위해서는 함수 내에 다음과 같이 sep=" , "라는 옵션을 추가해주면 됩니다.
> write.table(dat,'dat_exam2.txt', sep=",")